Лабораторная работа №4. Система генерации текста на основе префиксного дерева
Full API
Important
Описание лабораторных работ и другие полезные материалы доступны на сайте дисциплины
Дано
Текст на английском языке (
./assets/hp_letters.txt), который загружен и сохранен в переменнуюhp_lettersвstart.py
Текст на английском языке (
./assets/ussr_letters.txt), который загружен и сохранен в переменнуюussr_lettersвstart.py
В рамках предыдущей лабораторной работы вы выполнили задачу построения корпуса n-грамм и генерации текста на основе их частотности. Напомним, что для хранения последовательностей слов вы использовали словарь. Однако, на практике такой формат хранения может быть неэффективным. Например, как вы могли заметить, многие n-граммы имеют общие начальные последовательности, которые в словаре хранятся избыточное количество раз.
Проиллюстрируем проблему: представим, что в нашем корпусе есть 1000 n-грамм, которые начинаются со слов “я люблю”. Получается, что в итоговом словаре-хранилище будут 1000 раз записаны эти два слова, что задействует избыточный объем памяти.
Префиксное дерево решает эту проблему. Его структура позволяет хранить общие префиксы n-грамм только один раз, что значительно экономит память. В заключительной, четвертой лабораторной работе вам предстоит реализовать эту структуру данных и адаптировать под нее алгоритм генерации текста. Второе важное отличие от предыдущей работы заключается в том, что теперь вам предстоит обрабатывать текст на уровне слов, а не отдельных букв.
Структура префиксного дерева
В базовой реализации префиксное дерево состоит из набора связанных узлов, каждый из которых соответствует определенному символу:
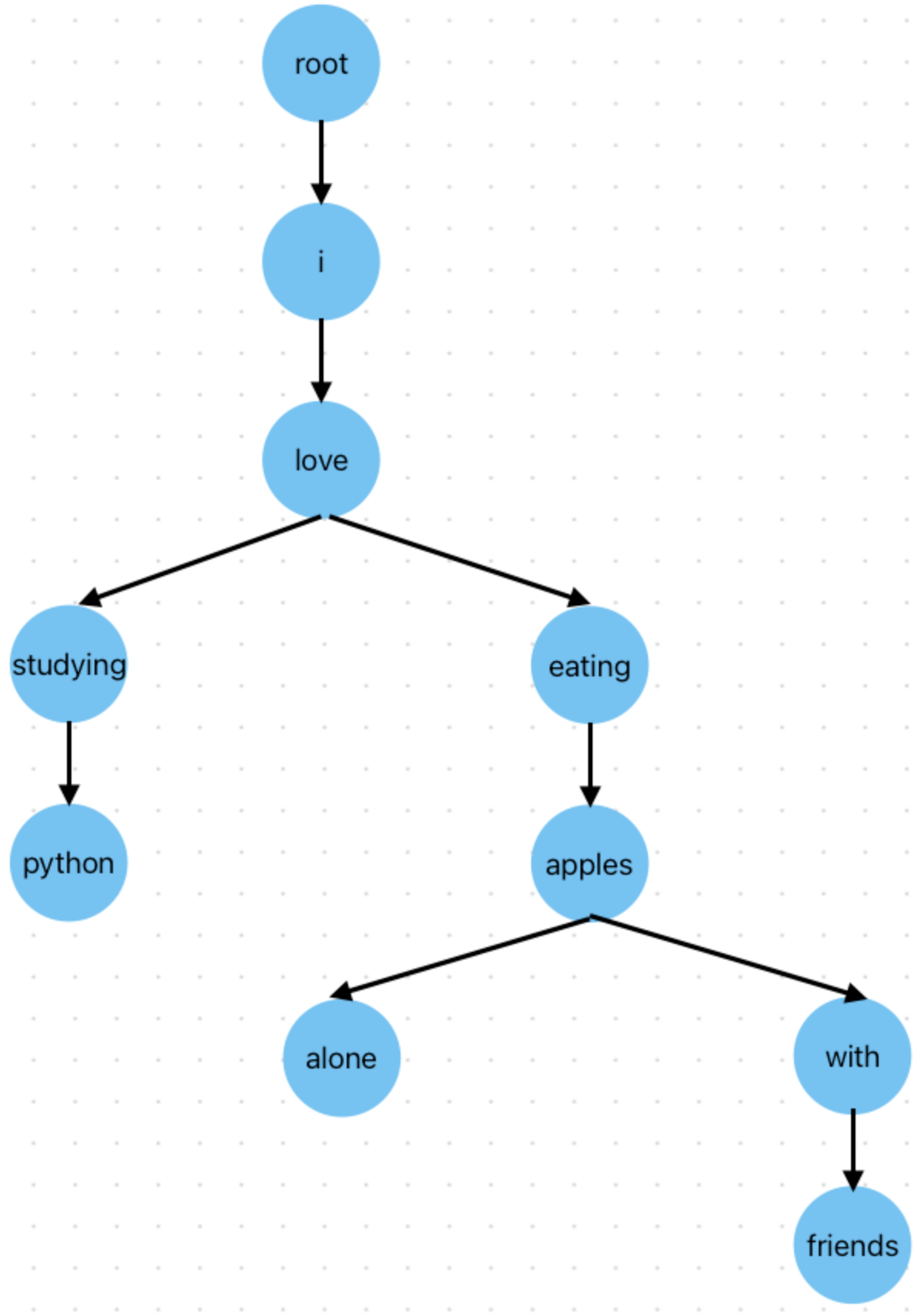
Структура префиксного дерева для данных последовательностей слов.
Как видно из картинки, все 4 n-граммы имеют минимальную общую начальную последовательность i love, и в случае, если бы мы использовали для их хранения словарь, этот “префикс” хранился бы 4 раза. В дереве же он сохраняется лишь единожды, что существенно снижает нагрузку на память при большом объеме данных. Подробнее про префиксные деревья вы можете прочитать здесь.
Каждый узел хранит в себе:
Соответствующий символ
Ссылки на дочерние узлы
Предположим, что у нас есть корпус закодированных слов 1, 2, 3, 4, 1, 2, 5, 6, 7, 1, 2, 3, 8, 9, 1, 2, 5, 10, 11, 1, 2, 3, 4, 12 и длина n-грамм - 3, тогда у нас будет следующий набор n-грамм:
(1,2,3) - 3 раза
(1,2,5) - 2 раза
(2,3,4) - 2 раза
(2,3,8) - 1 раз
(2,5,6) - 1 раз
(2,5,10) - 1 раз
(3,4,1) - 1 раз
(3,4,12) - 1 раз
(3,8,9) - 1 раз
(4,1,2) - 1 раз
(5,6,7) - 1 раз
(5,10,11) - 1 раз
(6,7,1) - 1 раз
(7,1,2) - 1 раз
(8,9,1) - 1 раз
(9,1,2) - 1 раз
(10,11,1) - 1 раз
(11,1,2) - 1 раз
Дерево этих n-грамм будет выглядеть так (корневой узел должен хранить в себе значение None):
root: [None | 0.0]
│
├── [1 | 0.0] → Начало триграмм (1,2,3), (1,2,5)
│ │
│ └── [2 | 0.0]
│ │
│ ├── [3 | 0.14] → (1,2,3)
│ │
│ └── [5 | 0.09] → (1,2,5)
│
│
├── [2 | 0.0] → Начало триграмм (2,3,4), (2,3,8), (2,5,6), (2,5,10)
│ │
│ ├── [3 | 0.0]
│ │ │
│ │ ├── [4 | 0.09] → (2,3,4)
│ │ │
│ │ └── [8 | 0.05] → (2,3,8)
│ │
│ └── [5 | 0.0]
│ │
│ ├── [6 | 0.05] → (2,5,6)
│ │
│ └── [10 | 0.05] → (2,5,10)
│
│
├── [3 | 0.0] → Начало триграмм (3,4,1), (3,4,12), (3,8,9)
│ │
│ ├── [4 | 0.0]
│ │ │
│ │ └── [1 | 0.05] → (3,4,1)
│ │ │
│ │ └── [12 | 0.05] → (3,4,12)
│ │
│ └── [8 | 0.0]
│ │
│ └── [9 | 0.05] → (3,8,9)
│
│
├── [4 | 0.0] → Начало триграммы (4,1,2)
│ │
│ └── [1 | 0.0]
│ │
│ └── [2 | 0.05] → (4,1,2)
│
│
├── [5 | 0.0] → Начало триграммы (5,6,7), (5,10,11)
│ │
│ ├── [6 | 0.0]
│ │ │
│ │ └── [7 | 0.05] → (5,6,7)
│ │
│ └── [10 | 0.0]
│ │
│ └── [11 | 0.05] → (5,10,11)
│
│
├── [6 | 0.0] → Начало триграммы (6,7,1)
│ │
│ └── [7 | 0.0]
│ │
│ └── [1 | 0.05] → (6,7,1)
│
│
├── [7 | 0.0] → Начало триграммы (7,1,2)
│ │
│ └── [1 | 0.0]
│ │
│ └── [2 | 0.05] → (7,1,2)
│
│
├── [8 | 0.0] → Начало триграммы (8,9,1)
│ │
│ └── [9 | 0.0]
│ │
│ └── [1 | 0.05] → (8,9,1)
│
│
├── [9 | 0.0] → Начало триграммы (9,1,2)
│ │
│ └── [1 | 0.0]
│ │
│ └── [2 | 0.05] → (9,1,2)
│
│
└── [10 | 0.0] → Начало триграммы (10,11,1)
│ │
│ └── [11 | 0.0]
│ │
│ └── [1 | 0.05] → (10,11,1)
│
│
└── [11 | 0.0] → Начало триграммы (11,1,2)
│ │
│ └── [1 | 0.0]
│ │
│ └── [2 | 0.05] → (11,1,2)
Как видно, каждый узел, являющийся концом n-граммы, хранит в себе относительную частоту данной n-граммы по отношению ко всему корпусу n-грамм. В конечном итоге программа должна автоматически дополнять изначальный промпт (начальную последовательность символов) до текста заданной длины посредством использования префиксного дерева.
В данной лабораторной работе генерация текста будет происходить следующим образом:
Алгоритм начинается с заданного промпта (начальной последовательности символов)
Из промпта берется контекст - последние (N-1) символов, где N - размер n-граммы
В префиксном дереве находится узел, соответствующий этому контексту
Среди всех дочерних узлов текущего контекста выбирается узел с наибольшей вероятностью
Символ, соответствующий выбранному узлу, добавляется к сгенерированной последовательности
Контекст обновляется: удаляется символ слева, добавляется новый в правую часть
Шаги 3-6 повторяются до достижения нужной длины текста
Для примера посмотрим на дерево выше и представим, что у нас есть закодированный промпт [1, 2], и мы хотим сгенерировать текст длиной 3 символа. Возьмем в качестве параметра размер n-грамм, равный двум. Таким образом, контекст будет содержать последние \(2 - 1\) слов из начальной последовательности, а именно [2]. После этого среди всех дочерних узлов текущего контекста выбирается наиболее вероятный. В нашем случае это узел со значением 3. Значение этого узла добавляется в конец последовательности, после чего контекст обновляется с [2] до [3]. Мы достигли заданной длины текста, работа алгоритма завершается. Мы получили закодированный текст [1, 2, 3].
Визуально процесс выше можно представить так:
Промпт: [1, 2]
Генерация первого символа: [2] → 3 (самый вероятный символ)
Итог: [1, 2, 3]
Это краткий обзор того, что вам предстоит сделать в рамках текущей работы, ознакомьтесь с ним и следуйте инструкциям ниже, чтобы реализовать полный алгоритм построения префиксного дерева и генерации текста посредством его использования.
UML-диаграмма классов

Что надо сделать
Шаг 0. Начать работу над лабораторной (вместе с преподавателем на практике)
Создайте форк репозитория.
Установите необходимые инструменты для работы.
Измените файлы
main.pyиstart.py.Закоммитьте изменения и создайте Pull request.
Important
В файле start.py вы должны написать код
для построения и использования префиксного дерева.
Для этого реализуйте функции в модуле main.py и импортируйте их в
start.py. Весь код, выполняющий операции с деревом, должен быть
выполнен в функции main в файле start.py:
def main() -> None:
pass
Вызов функции в файле start.py:
if __name__ == '__main__':
main()
В рамках данной лабораторной работы нельзя использовать модули collections, itertools, а также сторонние модули.
Шаг 1. Творческое задание (будет анонсировано преподавателем на лекции)
Important
Выполнение Шага 1 соответствует 4 баллам.
Шаг 2. Создать пользовательские исключения
Перед началом работы со структурой префиксного дерева и его составляющими вам необходимо реализовать несколько пользовательских исключений. Создание пользовательских исключений направлено на то, чтобы сделать код более читаемым и ясным. Например, вместо возврата None при ошибках в функциях можно создать для каждого типа ошибки собственное исключение, которое сразу укажет на место и тип ошибки, что существенно упрощает работу по отладке кода.
Для создания пользовательского исключения вам нужно создать новый класс, который наследуется от базового класса Exception. Внутри данного класса может находиться дополнительная логика обработки исключения или просто докстринг. В нашем случае второго варианта достаточно. Пример класса пользовательского исключения может выглядеть так:
1class CustomException(Exception):
2 """
3 Exception raised when something fails due to something
4 """
В данной лабораторной работе вам необходимо создать следующие исключения:
TriePrefixNotFoundError — поднимается, когда требуемый для перехода префикс отсутствует в дереве;
EncodingError — поднимается при сбое кодирования текста из-за неправильного ввода или ошибки обработки;
DecodingError — поднимается при сбое декодирования текста из-за неправильного ввода или ошибки обработки;
IncorrectNgramError — поднимается при попытке использовать неподходящий размер n-грамм;
MergeTreesError — поднимается в случае, когда невозможно совершить слияние деревьев.
Шаг 3. Определить класс для обработки слов
В прошлой лабораторной работе вы уже реализовывали класс для обработки текста, теперь вам необходимо создать на его основе новый класс для работы со словами и предложениями, а не с отдельными буквами.
Ваша задача - создать класс lab_4_auto_completion.main.WordProcessor,
являющийся наследником класса lab_3_generate_by_ngrams.main.TextProcessor,
который выполняет полный цикл обработки текста на уровне слов с сохранением структуры предложений.
Ключевое отличие: в родительском классе использовался разделитель слов под названием
end_of_word_token. Теперь, в дочернем классе, мы работаем не просто со словами, а с предложениями,
поэтому в качестве разделителя вводится новый атрибут: end_of_sentence_token.
Важно: функционально эти токены очень похожи — они оба являются специальными символами, разделяющими элементы текста. Разница лишь в том, на каком уровне (слов или предложений) они применяются.
Учитывая все вышесказанное, вам необходимо переиспользовать логику родительского класса, но с новым,
более подходящим названием токена. Реализуйте инициализатор класса: помимо объявления самого внутреннего
атрибута end_of_sentence_token инициализация должна включать еще и конструктор родительского класса, который
в качестве параметра end_of_word_token принимает атрибут end_of_sentence_token.
Шаг 3.1. Реализовать метод для токенизации текста
Переопределите метод lab_4_auto_completion.main.WordProcessor._tokenize(), который,
в отличие от одноименного метода родительского класса, разбивает текст на предложения, а не
отдельные слова.
Метод работает следующим образом:
Исходный текст разделяется на предложения
Каждое предложение обрабатывается следующим образом:
Предложение приводится к нижнему регистру
Предложение разбивается на слова по пробелам
Каждое слово очищается от небуквенных символов
Очищенное слово добавляется в результирующий массив
После последнего слова предложения добавляется end_of_sentence_token
3. Шаг 2 происходит до того момента, пока не будут обработаны все предложения, переданные во входной аргумент text.
Предположим, что на вход метода подано предложение Hello World! How are you?. На выходе у нас должен получиться кортеж, содержащий все обработанные предложения, в нашем случае (“hello”, “world”, “<EOS>”, “how”, “are”, “you”, “<EOS>”).
Обратите внимание: для разделения предложений в данной работе используется именно end_of_sentence_token, который в предыдущей лабораторной отвечал за разделение слов. Это сделано для того, чтобы не создавать в дочернем классе дополнительный атрибут, цель использования которого совпадает с целью атрибута родительского класса.
Note
В случае, если на вход метода подается неправильное значение или результирующий массив отсутствует, метод должен поднимать исключение EncodingError.
Шаг 3.2. Реализовать метод для вставки слов в хранилище
Переопределите метод lab_4_auto_completion.main.WordProcessor._put(). Одноименный метод
родительского класса добавлял только буквы в хранилище. Теперь же этот метод должен добавлять
слова в хранилище _storage.
Предположим, что метод получает на вход последовательно символы hello, world, hello, beautiful. Изначально хранилище содержит в себе только end_of_sentence_token. По мере вставки слов хранилище будет изменяться следующим образом:
_storage = {‘<EOS>’: 0, ‘hello’: 1} после вставки первого слова
_storage = {‘<EOS>’: 0, ‘hello’: 1, ‘world’: 2} после вставки второго слова
_storage = {‘<EOS>’: 0, ‘hello’: 1, ‘world’: 2} - ничего не происходит, слово hello уже есть
_storage = {‘<EOS>’: 0, ‘hello’: 1, ‘world’: 2, ‘beautiful’: 3} - после вставки последнего слова
Шаг 3.3. Реализовать метод для кодирования предложений
Реализуйте метод lab_4_auto_completion.main.WordProcessor.encode_sentences(), который
используется для кодирования текста на уровне предложений.
Метод работает следующим образом:
Входной текст разбивается на предложения, которые приводятся к нижнему регистру
Все непустые предложения обрабатываются следующим образом:
Каждое предложение разбивается на слова, которые очищаются от небуквенных символов
Слова добавляются в хранилище посредством метода
lab_4_auto_completion.main.WordProcessor._put(), после чего идентификатор каждого слова добавляется в список, который хранит данные о текущем предложенииВ конец предложения должен быть добавлен
end_of_sentence_token, после чего все текущее предложение должно быть добавлено в список всех закодированных предложений
Обратите внимание, что метод должен возвращать объект типа tuple - массив всех закодированных предложений.
Для примера возьмем текст, уже использованный ранее: Hello World! How are you?. Этот текст после обработки виде будет выглядеть следующим образом: [“hello world”, “how are you”]. После полной обработки методом encode_sentences результат будет выглядеть так: ((1, 2, 0), (3, 4, 5, 0)).
Шаг 3.4. Реализовать метод для обработки декодированного текста
Переопределите метод lab_4_auto_completion.main.WordProcessor._postprocess_decoded_text(),
который принимает на вход последовательность элементов, хранящуюся в кортеже decoded_corpus, и
возвращает строковое представление данной последовательности. Так, все входные
последовательности из кортежа объединяются в список строк, разделителем которых является
end_of_sentence_token. Соответственно, каждой строке соответствует одно предложение.
После этого все предложения должны объединиться через точку с пробелом, и первая буква каждого
предложения должна стать заглавной.
Например, метод получает на вход кортеж (“hello”, “world”, “<EOS>”, “how”, “are”, “you”, “<EOS>”). Результирующий массив будет выглядеть так: [“hello world”, “how are you”], а после финального преобразования будет возвращено значение “Hello world. How are you.”.
Note
В случае, если на вход метода подается неправильное значение или результирующий список строк отсутствует, метод должен поднимать исключение DecodingError.
После этого шага ваш класс для обработки текста готов. Теперь необходимо реализовать структуру префиксного дерева - непосредственную основу для будущего хранилища n-грамм.
Шаг 4. Определить сущность узла префиксного дерева
Каждое префиксное дерево состоит из узлов, связанных друг с другом. Узел представляет собой сущность, в которой хранится следующая информация:
Непосредственно элемент, соответствующий данному узлу (в нашем случае закодированное слово)
Ссылки на все дочерние узлы
В узлах дерева может храниться и другая информация, необходимая для конкретной задачи. Позже вы увидите, что в нашем случае является необходимым хранить частоту каждого слова, в противном случае было бы невозможно выбрать наилучших кандидатов для дополнения.
Шаг 4.1. Объявить сущность узла префиксного дерева
Реализуйте инициализатор класса lab_4_auto_completion.main.TrieNode.
Класс имеет 3 атрибута: 1 приватный и 2 защищенных:
__name - элемент, соответствующий данному узлу (обратите внимание, что в нашем случае тип элемента - целое число, так как далее вам предстоит закодировать слова в виде строк в числа)
_value — позже в нем мы будем хранить относительную частоту соответствующей n-граммы в корпусе. По умолчанию частота равна
0.0. Значение может быть обновлено позже методомlab_4_auto_completion.main.TrieNode.set_value()._children - список всех дочерних узлов
Все эти атрибуты должны быть объявлены при инициализации. На момент инициализации список дочерних узлов должен быть пуст.
Шаг 4.2. Реализовать метод, возвращающий элемент, хранящийся в данном узле
Реализуйте метод lab_4_auto_completion.main.TrieNode.get_name(), который
должен возвращать название элемента, который хранится в узле. Такие методы называются
геттерами. Геттеры обеспечивают один из основных принципов ООП - инкапсуляцию,
позволяя внешнему коду получать информацию о конфигурации узла без прямого доступа к
внутренним атрибутам класса. Подробнее про геттеры и связанные с ними сеттеры
вы можете прочитать в этом месте.
Шаг 4.3. Реализовать метод, возвращающий относительную частоту n-граммы
Реализуйте метод lab_4_auto_completion.main.TrieNode.get_value(), который должен
возвращать значение относительной частоты n-граммы, хранящейся в узле.
Шаг 4.4. Реализовать метод, устанавливающий значение частоты n-граммы
Реализуйте метод lab_4_auto_completion.main.TrieNode.set_value(), который должен
устанавливать в поле относительной частоты n-граммы значение, переданное в аргументе
new_value. Данный метод является примером сеттера.
Шаг 4.5. Реализовать метод, возвращающий дочерние узлы
Реализуйте метод lab_4_auto_completion.main.TrieNode.get_children(). На вход данного
метода может подаваться значение аргумента item, по умолчанию оно равняется None. В случае,
если значение аргумента не заполнено, метод должен вернуть кортеж всех дочерних узлов.
В случае, если значение аргумента item явно указано, должен возвращаться кортеж только из тех
дочерних узлов, значение которых равняется значению item.
Important
Данный метод должен использовать созданный вами на прошлом шаге метод
lab_4_auto_completion.main.TrieNode.get_name() для нахождения
значения дочерних узлов
Шаг 4.6. Переопределить служебный метод для проверки наличия дочерних узлов
Переопределите служебный метод lab_4_auto_completion.main.TrieNode.__bool__().
Метод должен вернуть True в случае, если узел имеет дочерние узлы.
По умолчанию Python считает объект True, если он не является:
None, False
числом 0 или 0.0
пустой коллекцией ([], {}, (), “”, set())
Класс TrieNode по умолчанию всегда возвращает True, поскольку не попадает под эти условия. Однако в контексте префиксного дерева логичнее связывать булево значение с наличием у узла дочерних узлов.
Предположим, у нас есть узел:
1without_children = TrieNode(__name=5, _value=0.4, _children=[])
2with_children = TrieNode(__name=5, _value=0.35, _children=[TrieNode(__name=7, _value=0.12, _children=[])])
3
4def check(node: TrieNode):
5 return bool(node)
6
7# Без переопределенного метода __bool__
8check(without_children) # Вернет True
9check(with_children) # Тоже вернет True
10# С переопределенным методом
11check(without_children) # Вернет False, так как дочерних узлов нет
12check(with_children) # Вернет True, так как есть дочерние узлы
Шаг 4.7. Реализовать метод, возвращающий результат проверки на наличие дочерних узлов
Реализуйте метод lab_4_auto_completion.main.TrieNode.has_children(), который должен
возвращать результат работы переопределенного метода
lab_4_auto_completion.main.TrieNode.__bool__(): возвращать True, если у узла есть
дочерние узлы, и False в обратном случае.
Шаг 4.8. Реализовать метод для добавления дочернего узла
Реализуйте метод lab_4_auto_completion.main.TrieNode.add_child(). Метод принимает
на вход значение item, после чего вставляет в массив дочерних узлов
объект класса TrieNode с этим значением, работа метода должна выглядеть так:
1node = TrieNode(__name=5, _value=0.55, _children=[])
2
3node.add_child(2) # Внутри метода создается объект TrieNode со значением 2 и добавляется в список
4 # дочерних узлов
5node.add_child(7) # Внутри метода создается объект TrieNode со значением 7 и добавляется в список
6 # дочерних узлов
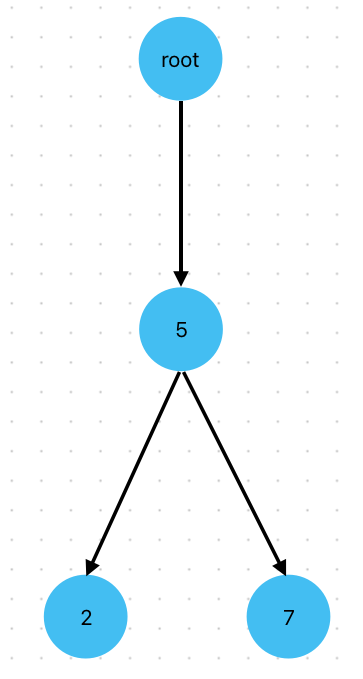
В результате данной операции дерево будет иметь такую структуру
Шаг 4.9. Переопределить служебный метод, возвращающий значение узла
Переопределите служебный метод lab_4_auto_completion.main.TrieNode.__str__(), который
должен возвращать строковое представление узла в формате
“TrieNode(name=XXX, value=XXX)”.
Работа метода может выглядеть так:
1node = TrieNode(__name=5, _value=0.42, _children=[])
2root = TrieNode(__name=None, _value=0.16, _children=[])
3
4str(node) # Выведет "TrieNode(name=5, value=0.42)"
5str(root) # Выведет "TrieNode(name=None, value=0.16)"
Шаг 5.1. Объявить сущность для построения базового префиксного дерева
Теперь, после создания сущности узла дерева, перейдем к реализации абстракции самого префиксного
дерева. Создайте класс lab_4_auto_completion.main.PrefixTrie.
Описание внутреннего атрибута: self._root - корневой узел, объект класса TrieNode.
Шаг 5.2. Реализовать алгоритм вставки последовательности в префиксное дерево
На данном этапе вам необходимо реализовать метод
lab_4_auto_completion.main.PrefixTrie._insert(), который выполняет операцию вставки
заданной последовательности sequence в дерево.
Работа метода выглядит следующим образом:
Задается переменная - текущий узел, для которого мы будем искать дочерние узлы. На начальном этапе текущим узлом является корневой узел
Если элемента заданной последовательности нет в списке дочерних узлов текущего узла, то надо создать его, а иначе - сделать его текущим и искать следующий элемент заданной последовательности для нового текущего узла
Алгоритм продолжается до тех пор, пока не будет произведен обход всей заданной последовательности
Note
Для поиска дочерних узлов и создания нужного дочернего узла метод должен использовать
реализованные вами ранее методы lab_4_auto_completion.main.TrieNode.get_children()
и lab_4_auto_completion.main.TrieNode.add_child().
Предположим, у нас есть дерево, состоящее только из корневого узла, и нам надо добавить в него последовательность (1, 2).
Первый элемент последовательности - 1, мы не нашли его в списке дочерних узлов корневого узла, поэтому создаем для корневого узла новый дочерний узел, хранящий значение 1, и переходим в этот узел.
Следующее значение префикса - 2, оно отсутствует среди дочерних узлов текущего узла (нашего только что созданного узла со значением 1), создаем для текущего узла новый дочерний узел со значением 2. В случае, если бы, например, в изначальном дереве помимо корневого узла уже был бы его дочерний узел со значение 1, то мы бы сразу перешли в него, и осталось бы добавить только узел со значением 2, являющийся дочерним для узла со значением 1.
Визуализация данного алгоритма выглядит следующим образом:
На первом этапе мы создаем дочерний узел корневого узла со значением 1:
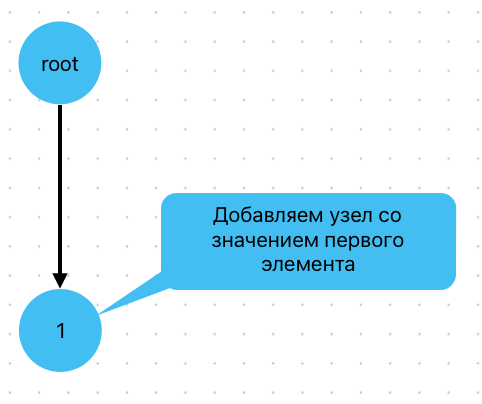
Далее переходим в только что созданный узел. Поскольку наша входная последовательность 1, 2 добавлена еще не полностью, создаем дочерний узел текущего узла:
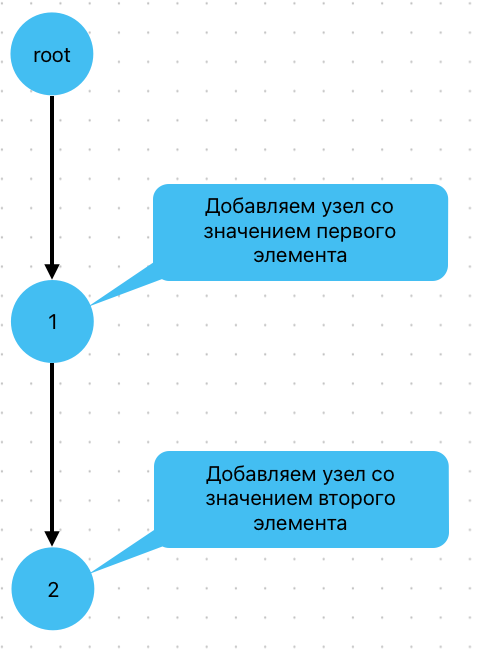
Шаг 5.3. Реализовать операцию очистки всего префиксного дерева
Реализуйте метод lab_4_auto_completion.main.PrefixTrie.clean(), задача которого - очистить
все префиксное дерево, сделав его пустым. Метод выполняет данную задачу посредством того, что создает
новый корневой узел, в результате чего все предыдущие данные удаляются.
Шаг 5.4. Реализовать операцию поиска по префиксу
Одна из базовых операций, связанных с префиксным деревом -
поиск по префиксу. Для выполнения этой операции реализуйте метод
lab_4_auto_completion.main.PrefixTrie.get_prefix().
Работа метода происходит следующим образом:
Задается переменная - текущий узел, для которого мы будем искать дочерние узлы. На начальном этапе текущим узлом является корневой узел
После этого для текущего узла находится дочерний узел, значение которого соответствует текущему элементу префикса, начиная с первого
Если такой узел не найден, должно быть поднято исключение TriePrefixNotFoundError, в обратном же случае найденный дочерний узел должен стать текущим
После обработки всех элементов префикса должен возвращаться конечный узел.
Ключевой момент: этот метод возвращает именно узел, соответствующий концу префикса, что позволяет продолжить работу с поддеревом.
Возьмем для примера часть дерева, которое было полностью показано в начале документа:
root: [None]
│
├── [1] → Начало триграмм (1,2,3), (1,2,5)
│ │
│ └── [2]
│ │
│ ├── [3] → (1,2,3)
│ │
│ └── [5] → (1,2,5)
│
│
├── [2] → Начало триграмм (2,3,4), (2,3,8), (2,5,6), (2,5,10)
│ │
│ ├── [3]
│ │ │
│ │ ├── [4] → (2,3,4)
│ │ │
│ │ └── [8] → (2,3,8)
│ │
│ └── [5]
│ │
│ ├── [6] → (2,5,6)
│ │
│ └── [10] → (2,5,10)
Вот как будет выглядеть результат работы данного метода для этого дерева:
1trie = PrefixTrie() # Предположим, что все нужные узлы уже были добавлены в дерево
2trie.get_prefix(2, 3, 8) # Вернет TrieNode(__name=8, _value=0.17)
3trie.get_prefix(1, 2, 5) # Вернет TrieNode(__name=2, _value=0.17)
Шаг 5.5. Найти все возможные продолжения для заданного префикса
Реализуйте метод lab_4_auto_completion.main.PrefixTrie.suggest(), задача которого -
вернуть все возможные последовательности, которые начинаются с данного префикса.
Алгоритм работы данного метода следующий:
При помощи метода
lab_4_auto_completion.main.PrefixTrie.get_prefix()производится поиск узла, соответствующего данному префиксу, переданному в аргументе prefixЕсли узел не найден, возвращается пустой массив
В остальных случаях происходит поиск всех возможных продолжений последовательности от найденного узла, в течение которого каждый следующий элемент добавляется к текущей последовательности до того момента, пока не будут достигнуты конечные узлы всех поддеревьев
Таким образом, метод находит все возможные продолжения заданного начала последовательности и создает готовые последовательности с этими продолжениями.
Для стандартизации вывода готовые последовательности возвращаются в порядке возрастания значений идентификаторов узлов.
Предположим, что у нас есть следующее дерево:
root: [None]
│
├── [1]
│ │
│ ├── [2]
│ │ │
│ │ ├── [3] → (1,2,3)
│ │ │
│ │ └── [4] → (1,2,4)
│ │
│ └── [5]
│ │
│ ├── [6] → (1,5,6)
│
├── [7]
│ │
│ ├── [8] → (7, 8)
1PrefixTrie.suggest((1, 2)) # Вернет результат [(1, 2, 3), (1, 2, 4)]
2PrefixTrie.suggest((1)) # Вернет результат [(1, 2, 3), (1, 2, 4), (1, 5, 6)]
3PrefixTrie.suggest((7, 8)) # Вернет результат [(7, 8)]
Шаг 5.6. Реализовать алгоритм построения префиксного дерева
Финальным шагом на оценку 6 является реализация алгоритма для построения префиксного дерева.
Реализуйте метод lab_4_auto_completion.main.PrefixTrie.fill(), который
сначала производит операцию очистки дерева, а после для каждого элемента
в заданном корпусе выполняет операцию вставки этого элемента в дерево при помощи метода
lab_4_auto_completion.main.PrefixTrie._insert(), реализованного вами в шаге 5.2. Таким образом
данный метод используется для построения полного дерева из входного набора символов. Так, если
в примере выше (в шаге 5.3) мы два раза вызывали метод
lab_4_auto_completion.main.PrefixTrie._insert() для вставки каждого символа, один вызов метода
lab_4_auto_completion.main.PrefixTrie.fill() приведет к созданию всего дерева.
Шаг 6. Продемонстрировать результаты в start.py
Important
Выполнение Шагов 1-6 соответствует 6 баллам.
Продемонстрируйте результат обновленной обработки текста и построения префиксного дерева
в функции main() модуля start.py. Текст писем про Гарри Поттера должен быть
закодирован посредством метода lab_4_auto_completion.main.WordProcessor.encode_sentences(),
после чего передан на вход метода lab_4_auto_completion.main.PrefixTrie.fill() для
построения дерева. Далее при помощи метода lab_4_auto_completion.main.PrefixTrie.suggest()
необходимо найти все продолжения для префикса со значением 2 и вывести на экран первую из
предложенных последовательностей в декодированном виде.
Бонусное задание
Выберите любой файл из папки
assets/secrets. В каждом таком файле содержится письмо студентов Хогвартса.Выполните чтения файла и найдите место, которое было сожжено.
По указанному ниже размеру N-gram извлеките контекст для генерации сожженного текста.
Сгенерируйте текст с помощью
lab_4_auto_completion.main.WordProcessor,NGramLanguageModelизlab_3_generate_by_ngrams.main.NGramLanguageModelи алгоритма Beam Searchlab_3_generate_by_ngrams.main.BeamSearcher.Вставьте сгенерированный текст на место пропуска в исходном письме.
Отправьте письмо своему ментору.
Используя следующую информацию для генерации:
Секрет 1: n_gram_size = 3, beam_width = 7, seq_len = 10
Секрет 2: n_gram_size = 3, beam_width = 5, seq_len = 15
Секрет 3: n_gram_size = 4, beam_width = 6, seq_len = 10
Секрет 4: n_gram_size = 2, beam_width = 7, seq_len = 10
Секрет 5: n_gram_size = 4, beam_width = 3, seq_len = 25
Important
Количество бонусов ограничено. Один студент может отгадать не более одной загадки. Поэтому только первые 5 студентов, которые справятся с заданием, смогут получить бонус. Решение о применении бонуса принимается ментором и не подлежит оспариванию. Студент получит бонус, только если на момент выполнения задания в его форке опубликован актуальный код, который позволяет воспроизвести результат.
Шаг 7. Реализовать языковую модель на основе n-граммного дерева с помощью NGramTrieLanguageModel
Чтобы использовать n-граммное дерево для генерации текста, необходимо объединить
структуру данных с логикой обработки корпуса и предсказания следующих токенов.
Класс lab_4_auto_completion.main.NGramTrieLanguageModel
инкапсулирует эту логику: он строит дерево из корпуса, вычисляет относительные частоты всех n-грамм
и предоставляет методы для получения вероятных продолжений заданного контекста.
Шаг 7.1. Инициализировать класс NGramTrieLanguageModel
Класс lab_4_auto_completion.main.NGramTrieLanguageModel должен быть инициализирован
двумя параметрами (т.е. аргументами):
encoded_corpus— кортеж закодированных предложений (или None при создании пустой модели),n_gram_size— целое положительное число, задающее размер окна для построения n-грамм.
Внутри инициализатора:
Вызывается
NGramLanguageModel.__init__(self, encoded_corpus, n_gram_size), чтобы установить атрибуты_encoded_corpusи_n_gram_size.Корневой узел _root инициализируется как экземпляр
lab_4_auto_completion.main.TrieNode(без аргументов, с частотой по умолчанию 0.0).
Класс NGramTrieLanguageModel использует существующий класс TrieNode,
который уже поддерживает хранение частоты через атрибут _value
и методы get_value() и set_value().
Шаг 7.2. Реализовать метод получения размера n-граммы
Реализуйте метод lab_4_auto_completion.main.NGramTrieLanguageModel.get_n_gram_size().
Он возвращает значение размера n-граммы, заданное при создании экземпляра.
Шаг 7.3. Реализовать вспомогательные методы для поиска и сбора частот
Чтобы модель могла предлагать наиболее вероятные продолжения заданного контекста, ей необходимо уметь находить нужный узел в дереве и собирать информацию о возможных следующих токенах. Эти задачи реализуются с помощью трёх вспомогательных методов:
lab_4_auto_completion.main.NGramTrieLanguageModel.get_node_by_prefix()— возвращает узел, соответствующий префиксуprefix, вызывая унаследованный методself.get_prefix(prefix),lab_4_auto_completion.main.NGramTrieLanguageModel._collect_frequencies()— собирает и возвращает словарь вида{токен: частота}, где:токен — значение
nameдочернего узла (используйте методget_name()),частота — значение
_valueдочернего узла (используйте методget_value()),
lab_4_auto_completion.main.NGramTrieLanguageModel.get_next_tokens()— находит узел поstart_sequence(для справки (не нужно вычислять в методе): по срезу последнихn_gram_size - 1токенов из входной последовательностиsequence) с помощью унаследованного методаself.get_prefix(prefix), проверяет наличие детей:Если детей нет — возвращается пустой словарь.
Если дети есть — вызывается метод
lab_4_auto_completion.main.NGramTrieLanguageModel._collect_frequencies()и возвращает результат.
Шаг 7.4. Реализовать метод сбора всех n-грамм из дерева
Реализуйте метод lab_4_auto_completion.main.NGramTrieLanguageModel._collect_all_ngrams().
Он должен делать следующее:
Обход дерева, начиная с корня
self._root.Сбор всех последовательностей токенов длиной
n_gram_size.Возврат списка всех полных n-грамм, хранящихся в дереве.
Например, возвращаемое значение может выглядеть так:
[(10, 25, 33), (25, 33, 41), (33, 41, 5)]
Каждая n-грамма представлена как кортеж целых чисел, где числа — это ID токенов.
Шаг 7.5. Вычислить и присвоить относительные частоты n-граммам
Реализуйте метод lab_4_auto_completion.main.NGramTrieLanguageModel._fill_frequencies().
Он принимает на вход кортеж полных n-грамм (например, ((1, 2, 3), (2, 3, 4), ...)),
извлечённых из дерева методом
lab_4_auto_completion.main.NGramTrieLanguageModel._collect_all_ngrams().
Алгоритм работы:
Подсчитывается абсолютная частота каждой уникальной n-граммы в переданном списке.
Вычисляется общее количество n-грамм (длина входного кортежа).
Для каждой n-граммы вычисляется её относительная частота как:
Эта частота присваивается последнему узлу соответствующей n-граммы в дереве через метод
lab_4_auto_completion.main.TrieNode.set_value(). Узел находится вызовомself.get_prefix(ngram).
Таким образом, в каждом листовом узле, соответствующем завершению полной n-граммы, хранится её глобальная относительная частота в корпусе.
Эти частоты используются методом
lab_4_auto_completion.main.NGramTrieLanguageModel.generate_next_token()
для выбора наиболее вероятного продолжения:
среди дочерних узлов заданного контекста выбирается тот, у которого частота выше.
Note
Листовыми узлами называют узлы без дочерних элементов. В данной реализации
все полные n-граммы завершаются именно в листовых узлах, так как дерево
содержит только последовательности длины n_gram_size.
Шаг 7.6. Реализовать метод построения дерева
Реализуйте метод lab_4_auto_completion.main.NGramTrieLanguageModel.build(). Он
строит модель префиксного дерева из корпуса. Дерево должно:
Строиться на основе скользящего окна фиксированного размера
n_gram_sizeХранить только полные n-граммы (длиной ровно
n_gram_size)После построения автоматически вычислять относительные частоты всех n-грамм и сохранять их в узлах, соответствующих последним токенам полных n-грамм (которые в данной реализации совпадают с листовыми узлами, так как дерево строится только из последовательностей длины
n_gram_size).
Если создание дерева прошло успешно, возвращается 0. В противном случае 1.
Note
Скользящее окно длины n_gram_size — это способ извлечения всех
подпоследовательностей фиксированной длины из последовательности токенов
так, что при этом окно сдвигается на один токен при каждом новом шаге — без пропусков.
Например, пусть у вас есть последовательность токенов (10, 20, 30, 40, 50) и n_gram_size = 3. Тогда скользящее окно длины 3 с шагом 1 даст следующие n-граммы:
(10, 20, 30) — окно на позициях 0, 1 и 2
(20, 30, 40) — сдвинули окно на 1 вправо → позиции с первой по третью
(30, 40, 50) — снова сдвиг на 1 → позиции 2, 3 и 4
Note
В начале каждого вызова метода
lab_4_auto_completion.main.NGramTrieLanguageModel.build()
необходимо обнулять дерево, то есть нужно повторно (как в методе
lab_4_auto_completion.main.NGramTrieLanguageModel.__init__()) инициализировать
атрибут self._root. Это требуется для того, чтобы метод работал именно
с текущим корпусом.
Note
В рамках этого метода после формирования всех n-грамм
с помощью скользящего окна и их вставки в дерево
обязательно последовательно вызываются два метода:
сначала lab_4_auto_completion.main.NGramTrieLanguageModel._collect_all_ngrams(),
чтобы получить полный список n-грамм, хранящихся в дереве, а затем
lab_4_auto_completion.main.NGramTrieLanguageModel._fill_frequencies(),
которому передаётся этот список для вычисления и присвоения частот.
Шаг 7.7. Реализовать метод расширения модели и обновления частот
Реализуйте метод lab_4_auto_completion.main.NGramTrieLanguageModel.update(). Он
должен расширять существующую модель новыми n-граммами из дополнительного корпуса
и пересчитывать частоты на основе объединённого корпуса.
В рамках метода обязательно использовать атрибут self._encoded_corpus. Он хранит
текущий закодированный корпус в виде кортежа
последовательностей токенов (предложений). При вызове метода
lab_4_auto_completion.main.NGramTrieLanguageModel.update():
Если
self._encoded_corpusравенNoneили пуст, он инициализируется как переданный новый корпус (new_corpus).Если
self._encoded_corpusуже содержит данные, к нему добавляется новый корпус.
После обновления значения self._encoded_corpus необходимо вызвать
lab_4_auto_completion.main.NGramTrieLanguageModel.build(),
чтобы полностью перестроить дерево и заново вычислить относительные частоты
на основе всего объединённого корпуса.
Шаг 7.8. Реализовать метод генерации возможных следующих токенов
Ключевая функция языковой модели — предсказание наиболее вероятных продолжений
заданной последовательности. Эту задачу решает метод
lab_4_auto_completion.main.NGramTrieLanguageModel.generate_next_token().
Метод принимает на вход произвольную последовательность токенов и:
Если входной аргумент не является непустым кортежем, метод возвращает
None.Если длина входной последовательности меньше
n_gram_size - 1, метод возвращаетNone(недостаточно контекста для предсказания).Если всё в порядке, метод извлекает последние
n_gram_size - 1токенов как контекст.Далее метод вызывает
lab_4_auto_completion.main.NGramTrieLanguageModel.get_next_tokens(), передавая ему этот контекст (внутриlab_4_auto_completion.main.NGramTrieLanguageModel.get_next_tokens()выполняется поиск узла, соответствующего контексту):Если контекст не найден в дереве, выбрасывается исключение
TriePrefixNotFoundError, и метод возвращает пустой словарь{}.Если контекст найден,
lab_4_auto_completion.main.NGramTrieLanguageModel.get_next_tokens()собирает все дочерние узлы и возвращает словарь вида{токен: частота}.
Шаг 7.9. Переопределить строковое представление модели
Переопределите метод lab_4_auto_completion.main.NGramTrieLanguageModel.__str__().
Строка должна возвращаться в формате NGramTrieLanguageModel(X), где X — значение
атрибута self._n_gram_size, заданное при инициализации модели. Например, если модель создана
при n_gram_size=3, то вызов str(model) должен вернуть строку
NGramTrieLanguageModel(3).
Шаг 8. Продемонстрировать результаты в start.py
Important
Выполнение Шагов 1-8 соответствует 8 баллам.
Продемонстрируйте результат в функции main() модуля start.py.
Постройте модель на основе корпуса
assets/hp_letters.txt. Для этого:Загрузите текст с помощью
WordProcessor,Закодируйте его в последовательности токенов с помощью
lab_4_auto_completion.main.WordProcessor.encode_sentences(),Создайте экземпляр
lab_4_auto_completion.main.NGramTrieLanguageModelс параметрамиencoded_corpusи подходящим значениемn_gram_size(например, 5),Вызовите метод
lab_4_auto_completion.main.NGramTrieLanguageModel.build().
Добавьте второй корпус
assets/ussr_letters.txtчерез методlab_4_auto_completion.main.NGramTrieLanguageModel.update(), чтобы расширить контекстную базу.Продемонстрируйте генерацию текста. Для этого создайте экземпляры генераторов из лабораторной работы 3:
lab_3_generate_by_ngrams.main.GreedyTextGenerator(жадный выбор),lab_3_generate_by_ngrams.main.BeamSearchTextGenerator(beam search).
Note
Оба генератора принимают в качестве аргументов
вашу модель (NGramTrieLanguageModel) и WordProcessor.
Далее вызовите метод lab_3_generate_by_ngrams.main.GreedyTextGenerator.run()
и выведите результат для каждого генератора до и после вызова
lab_4_auto_completion.main.NGramTrieLanguageModel.update().
Сравните качество генерации:
Проанализируйте, как изменяется сгенерированный текст до и после объединения корпусов.
Сравните результаты жадного алгоритма и beam search: какой из них даёт более связный, разнообразный или интересный текст?
Шаг 9. Обучить динамическую модель префиксного дерева
Теперь, когда Вы научились успешно использовать модель префиксного дерева на основе n-грамм, Вам предстоит усовершенствовать её. Для этого Вам нужно реализовать и обучить модель динамического дерева.
В отличии от предыдущей модели префиксного дерева на основе n-грамм, динамическая модель подразумевает использование целых предложений, а не просто n-грамм нужной длины. Внутри динамической модели рассматриваются все возможные длины n-грамм (от 2 до некоторого лимитного значения), и на основе каждой из этих длин строится модель. Все эти модели затем могут использоваться при дальнейшей генерации, чтобы улучшить качество результата.
Идея состоит в том, что когда мы обучаем только одну модель и используем её, мы никогда не застанем случаи, когда при другой длине n-грамм может попасться более вероятная последовательность для генерации. Использование динамической модели решит эту проблему.
Чтобы реализовать динамическую модель, Вам предстоит выполнить слияние деревьев на основе всех рассматриваемых n-грамм. Слияние — это процесс, при котором деревья объединяются в одно большое дерево. Таким образом в рамках одной структуры для поиска токенов будут доступны все вариации модели с разными n-граммами.
Шаг 9.1. Инициализировать динамическую модель префиксного дерева
Реализуйте инициализацию класса lab_4_auto_completion.main.DynamicNgramLMTrie,
наследующегося от NGramTrieLanguageModel.
Данный класс имеют следующие атрибуты:
_root— корневой узел дерева в его изначальном (пустом) состоянии;_encoded_corpus- закодированные данные, на основе которых генерируется текст;_current_n_gram_size— текущий размер рассматриваемых n-грамм, на момент инициализации равный 0;_max_ngrams_size— наибольшее вероятное значение n-грамм для рассмотрения. В качестве него берётся значениеn_gram_size, передаваемое при инициализации экземпляра класса. По умолчанию оно равно 3._models— словарь, содержащий пары значенийдлина n-грамм: модель, где хранятся все экземпляры моделей, обученных на нужной длине n-грамм. При инициализации в атрибуте хранится пустой словарь.
Шаг 9.2. Подготовить деревья к слиянию
Как уже было сказано, потенциальное преимущество в использовании динамической модели дерева на основе n-грамм состоит в том, чтобы не упускать наиболее вероятные случаи генерации n-грамм, которые встречаются при разной их длине.
Для того, чтобы использовать все эти модели вместе, совершим слияние деревьев в одно большое, динамическое.
Для выполнения слияния деревьев в динамическое Вам понадобится обрабатывать существующие n-граммные деревья и уметь копировать данные из одного дерева в другое. Те узел или дерево, которые копируются, назовём копируемые; те узел или дерево, в которые производится копирование, назовём принимающие.
Для того, чтобы выполнить слияние, Вам потребуется оперировать корневыми узлами деревьев.
Дополните NGramTrieLanguageModel геттером
lab_4_auto_completion.main.NGramTrieLanguageModel.get_root(),
который возвращает корневой узел дерева.
Шаг 9.3. Реализовать вспомогательный метод для копирования дочернего узла
Реализуйте метод
lab_4_auto_completion.main.DynamicNgramLMTrie._assign_child(),
который отвечает за получение дочернего узла с именем node_name или создание
нового узла, если он отсутствует в родительском дереве.
Метод используется при слиянии деревьев и обеспечивает корректное формирование структуры поддеревьев.
Перед выполнением поиска необходимо проверить корректность параметра node_name:
значение должно быть целым числом и не меньше нуля.
В противном случае требуется поднять исключение ValueError с соответствующим сообщением.
При наличии у родительского узла parent ребёнка с именем node_name
необходимо вернуть существующий узел.
Если передано значение freq и оно отлично от 0.0, обновите частоту у найденного узла.
Если узел с таким именем отсутствует — создайте его, после чего извлеките созданный узел через
и установите ему значение freq, если оно передано.
Метод должен возвращать найденный или созданный дочерний узел.
Note
В результате работы этого метода аргумент parent может измениться,
и эти изменения будут доступны вне метода, несмотря на то, что мы не
возвращаем его. Этот факт позволит нам в дальнейшем
заполнить динамическое дерево, не переопределяя каждый из его изменяемых
узлов вручную.
Почему это работает без возвращения переменных?
Обратите внимание, что любой TrieNode, в том
числе и корневой, содержит в себе информацию об
узлах детей в виде списка. Подумайте, какое свойство
списков в Python влияет на возможность заполнять их
без переопределения.
Шаг 9.4. Скопировать дерево
Для объединения нескольких n-граммных деревьев в одно динамическое необходимо уметь поочерёдно «вклеивать» структуры меньших деревьев в общее результирующее. В простейшем случае это означает перенос всех потомков корневого узла копируемого дерева в динамическое дерева, соблюдая исходную иерархию и частоты.
Реализуйте защищённый метод
lab_4_auto_completion.main.DynamicNgramLMTrie._insert_trie(),
который принимает на вход корневой узел копируемого дерева и вставляет
все его поддеревья в динамическое дереве.
Метод должен работать итеративно, используя стек. Каждый элемент стека содержит пару узлов: корень поддерева источника и соответствующий узел-приёмник в динамическом дереве.
Для каждого дочернего узла копируемого дерева нужно найти место в динамическом дереве, куда будет интегрироваться нужное поддерево.
Каждая итерация должна завершаться добавлением новой пары в стек: текущего дочернего узла и узла, найденного среди дочерних узлов узла-приёмника.
Таким образом, метод полностью копирует структуру дерева источника в дерево назначения,
сохраняя корректную частотную информацию и структуру предшествующих n-грамм.
В результате работы алгоритма в атрибут _root будет интегрировано копируемое дерево.
Important
На данном шаге необходимо использовать следующие методы:
lab_4_auto_completion.main.TrieNode.get_name(),
lab_4_auto_completion.main.TrieNode.get_value(),
lab_4_auto_completion.main.TrieNode.get_children() и
lab_4_auto_completion.main.DynamicNgramLMTrie._assign_child().
Шаг 9.5. Выполнить слияние деревьев
После того как Вы построили отдельные n-граммные модели для всех размеров
от 2 до максимального N, необходимо объединить их в единую структуру —
динамическое n-граммное дерево.
Реализуйте защищённый метод
lab_4_auto_completion.main.DynamicNgramLMTrie._merge(),
который отвечает за последовательное добавление всех построенных деревьев
в одно итоговое.
В процессе работы метода следует инициализировать новый корневой узел
и последовательно интегрировать в него все деревья из _models
(в порядке возрастания размеров n-грамм) с использованием метода
lab_4_auto_completion.main.DynamicNgramLMTrie._insert_trie().
В результате работы метода атрибут _root заполняется структурой, в которую
интегрированы все n-граммные деревья.
Note
Если атрибут _models на момент вызова метода является пустым,
то есть не содержит моделей, поднимите исключение
MergeTreesError.
Шаг 9.6. Построить новое дерево на основе всех длин n-грамм
Реализуйте метод
lab_4_auto_completion.main.DynamicNgramLMTrie.build(),
который отвечает за построение (N - 1) моделей и их слияние
в одно большое дерево. N здесь — максимальное количество n-грамм.
Для каждого создаваемой модели обязательным является построение дерева с помощью
lab_4_auto_completion.main.NGramTrieLanguageModel.build().
Все модели после создания должны сохраняться в словарь _models.
После заполнения _models совершите слияние моделей с помощью метода
lab_4_auto_completion.main.DynamicNgramLMTrie._merge().
Если построение моделей и их слияние прошло успешно, метод должен возвращать 0, иначе 1.
Шаг 10. Создать BackOff генератор для динамического дерева
В лабораторной работе №3 Вы познакомились с алгоритмом BackOff для генерации текста. В отличии от Beam Search, он опирается на выбор наиболее вероятного продолжения последовательности из нескольких моделей одновременно, и это делает его более устойчивым. Подробнее в лабораторной №3 и других источниках.
Данный алгоритм — самый подходящий для работы со структурой динамического дерева, поэтому именно его Вам и предлагается использовать.
Шаг 10.1. Инициализировать DynamicBackOffGenerator
При инициализации класса на вход подаются экземпляры
lab_4_auto_completion.main.DynamicNgramLMTrie
и lab_4_auto_completion.main.WordProcessor.
Используйте DynamicNgramLMTrie в качестве требуемых моделей.
Помимо атрибутов наследуемого класса, DynamicBackOffGenerator
имеет защищённый атрибут _dynamic_trie, с которым, для удобства,
и будет проводиться основная работа.
Шаг 10.2. Задать текущий размер n-грамм
Для успешного выбора и генерации следующего токена важно знать, на какой из размеров n-грамм, поддерживаемых динамическим деревом, мы смотрим в конкретный момент.
Расширьте функционал динамического дерева сеттером
lab_4_auto_completion.main.DynamicNgramLMTrie.set_current_ngram_size(),
который задаёт текущий максимальный размер n-грамм для генерации.
Note
В случае, если в метод передаётся некорректное значение аргумента или размер заданной n-граммы менее 2 или более значения атрибута _max_ngram_size, поднимите исключение IncorrectNgramError
Шаг 10.3. Продолжить последовательность
Расширьте NGramTrieLanguageModel методом
lab_4_auto_completion.main.DynamicNgramLMTrie.generate_next_token().
Данный метод принимает на вход последовательность закодированных токенов. Метод отрезает из последовательности всё, кроме контекста, по которому необходимо определить вероятность каждого из потенциальных следующих токенов. Контекст составляет N-1 последних элементов последовательности. N в данном случае — текущий размер n-грамм. Если входная последовательность меньше по размеру, чем размер n-граммы, то за максимальный контекст примите длину последовательности.
От Вас требуется найти в дереве (начиная с дочерних узлов корня динамического дерева) узлы, соответствующие значениям каждого из токенов контекста.
Задача алгоритма — по ветвлениям дерева дойти до того узла, который является последним членом контекста, и все родители которого последовательно составляют остальной контекст.
Если ни один дочерний узел не найден на любом из этапов, поиск прекращается, и возвращается пустой словарь.
Для последнего найденного узла контекста следует рассмотреть каждого из его детей — это будут кандидаты для продолжения последовательности. Запишите их в итоговый словарь. В качестве ключей словаря используйте идентификатор узла, а в качестве значений используйте значения частот, хранящиеся в узлах. Если в узле не сохранены значения частот, такой узел следует пропустить.
В результате, у Вас должен получиться словарь из идентификаторов узлов и частот.
Note
Если введенная последовательность не является кортежем или кортеж пустой,
возвращается None.
Important
На данном шаге необходимо использовать следующие методы:
lab_4_auto_completion.main.TrieNode.get_children(),
lab_4_auto_completion.main.TrieNode.get_name() и
lab_4_auto_completion.main.TrieNode.get_value().
Шаг 10.4. Получить следующий токен из динамического дерева
Переопределите метод
lab_4_auto_completion.main.DynamicBackOffGenerator.get_next_token(),
который возвращает словарь, ключами которого являются буквы-кандидаты, а значениями
вероятности буквы кандидата.
Вам необходимо:
Выбрать максимальный размер n-грамм. Если длина входящей последовательности меньше максимального размера n-грамм в дереве, нужно принять максимальный размер n-грамм за длину входящей последовательности.
Отсортировать размеры N–грамм в порядке убывания;
Задать текущую длину n-грамм для дерева;
Получить все токены-кандидаты для генерации в виде словаря;
В случае, если токенов-кандидатов для заданной длины n-грамм нет или вызываемый метод возвращает
None, необходимо перейти к N–грамме меньшего размера и вернуться на шаг 3.
В данном методе необходимо использовать методы
lab_4_auto_completion.main.NGramTrieLanguageModel.get_n_gram_size(),
lab_4_auto_completion.main.DynamicNgramLMTrie.set_current_ngram_size() и
lab_4_auto_completion.main.DynamicNgramLMTrie.generate_next_token().
Note
Если на вход подается некорректное значение аргумента (кортеж пустой),
то метод возвращает None.
Если список размеров N–грамм пустой, то метод также возвращает None.
Шаг 10.5. Сгенерировать последовательность
Переопределите метод
lab_4_auto_completion.main.DynamicBackOffGenerator.run()
На данном шаге Вам следует:
Закодировать заданную последовательность (промпт)
Получить все буквы-кандидаты для генерации. Используйте уже реализованный метод класса
DynamicBackOffGenerator;Жадно выбирать кандидата с наибольшей вероятностью и добавить его к последовательности;
Повторять шаги 2 и 3 до тех пор, пока не получим заданную длину последовательности;
Декодировать полученную последовательность.
В случае, если буквы-кандидаты не были найдены, то генерация прекращается.
Метод возвращает сгенерированный текст в виде строки.
В данном методе необходимо использовать методы
lab_3_generate_by_ngrams.main.TextProcessor.encode() и
lab_3_generate_by_ngrams.main.TextProcessor.decode(),
наследуемые через WordProcessor
а также метод
lab_4_auto_completion.main.DynamicBackOffGenerator.get_next_token().
Note
Если на вход подаются некорректные значения (количество букв для
генерации не является целым числом или число отрицательное, а также
промпт не является строкой или строка пустая), то метод возвращает None.
Шаг 11. Сохранить модель
Часто, чтобы не строить модель заново каждый раз, полезно сохранять текущее состояние её параметров и переиспользовать их при повторном вызове или инициализации. В нашем случае такими параметрами является вся структура динамического дерева.
Реализуйте функцию lab_4_auto_completion.main.save(), которая
отвечает за сохранение структуры дерева в файл, путь до которого указывается
при вызове функции.
Дерево должно быть выгружено в формате JSON. Подробнее структуру того, как должен выглядеть полученный файл, вы можете найти в примере.
Шаг 12. Загрузить модель
Сохранённую модель затем следует уметь загрузить обратно для дальнейшего использования.
Реализуйте функцию lab_4_auto_completion.main.load(), которая отвечает
за загрузку дерева обратно в экземпляр класса
lab_4_auto_completion.main.DynamicNgramLMTrie.
Шаг 13. Продемонстрировать результаты в start.py
Important
Выполнение Шагов 1-13 соответствует 10 баллам.
Постройте модель на основе корпуса assets/hp_letters.txt. Для этого:
Загрузите текст с помощью
WordProcessor,Закодируйте его в последовательности токенов с помощью
lab_4_auto_completion.main.WordProcessor.encode_sentences(),Создайте экземпляр
lab_4_auto_completion.main.DynamicNgramLMTrieс параметрамиencoded_corpusи подходящим значениемn_gram_size(например, 5),Вызовите метод
lab_4_auto_completion.main.DynamicNgramLMTrie.build().
Продемонстрируйте сохранение и загрузку модели.
Продемонстрируйте генерацию текста. Для этого создайте экземпляр динамического генератора
lab_4_auto_completion.main.DynamicBackOffGenerator. Запустите генерацию со следующими параметрами: промпт — “Ivanov” и длина генерируемого продолжения — 50.Добавьте второй корпус assets/ussr_letters.txt через метод
lab_4_auto_completion.main.NGramTrieLanguageModel.update(), чтобы расширить контекстную базу.Продемонстрируйте генерацию текста на обновлённом дереве с теми же параметрами.
Сравните качество генерации:
Проанализируйте, как изменяется сгенерированный текст до и после объединения корпусов.
Сравните результаты жадного алгоритма, Beam Search и BackOff c динамическим деревом: какой из них даёт более связный, разнообразный или интересный текст?